学了一阵子python后,心痒痒想爬个网站试试,但得找个自己感兴趣的啊,那必然是篮球了。想了想平时看篮球的也就腾讯和虎扑,细心的jrs可能会发现腾讯体育点进球员个人主页会有五角形的能力分布图,虎扑则是各类数据比较详尽,所以博主就想着是不是可以爬一爬虎扑,然后做个球员的能力分布图。
话不多说,先上张效果图
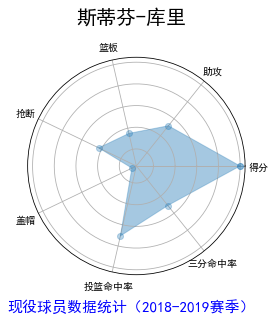
输入对应球员名字就可以获得相应球员的能力分布图了,话说最终效果还是不错的!
将我们的实现过程分为两步,第一,爬取虎扑网页上球员的个人信息,存入文件中;第二,读取文件,制作球员能力分布图
首先,打开虎扑网页[https://nba.hupu.com/stats/players/pts](这个我称之为页面一,后面都这样叫了)
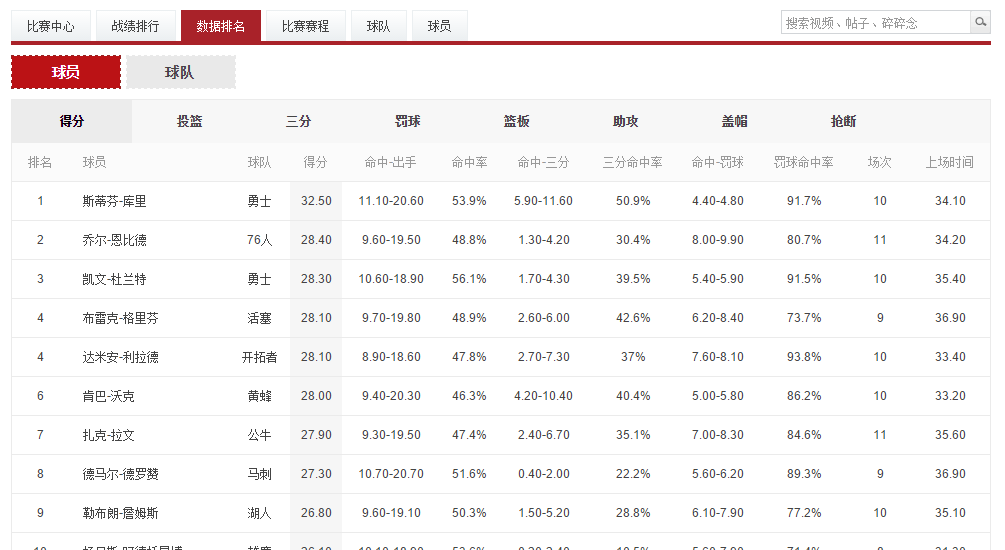
我们观察发现虎扑有个数据网页,有各个球员对应的部分信息,是部分信息,这个网页只有与球员得分有关的信息,球员的详尽信息要点击球员的名字进去,然后我们点击斯蒂芬-库里进去
(这个我称之为页面二,后面都这样叫了))
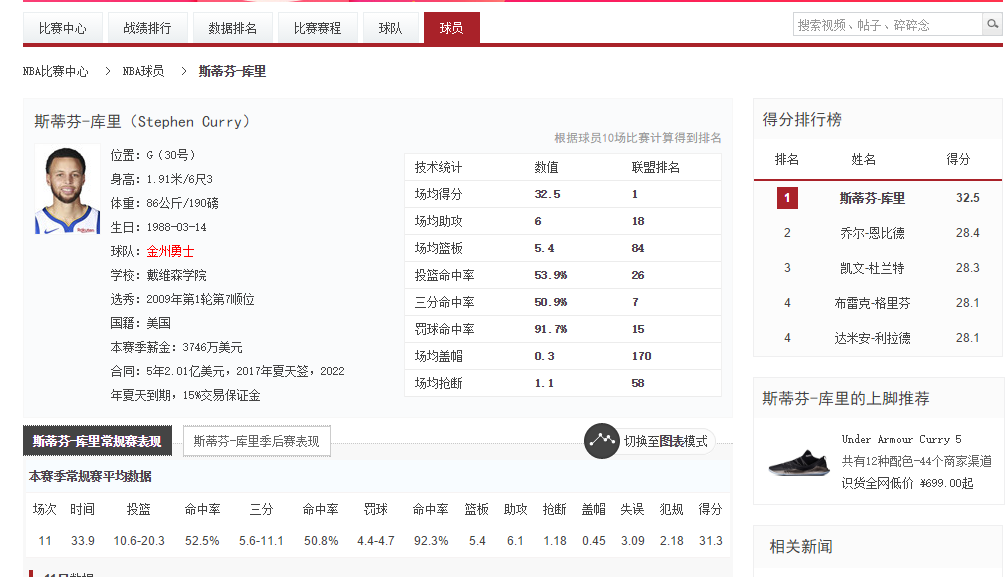
发现这里有库里的各类信息,而我们要提取的就是得分、助攻、抢断、篮板、盖帽、投篮命中率、三分命中率信息。
看到这里,基本的想法就出现了,我们可以通过打开球员得分排行榜的那个网页(也就是页面一),然后一个一个点击球员的名字进入到球员个人主页(页面二)获取我们想要的信息。
然后我们就要分析网页的源代码了
使用浏览器的检查地位功能(页面一)

发现球员的名字都存在‘td,left’里,所以我们只要定位这个标签,然后再模拟浏览器点击(click())进个人主页就好了(页面二)
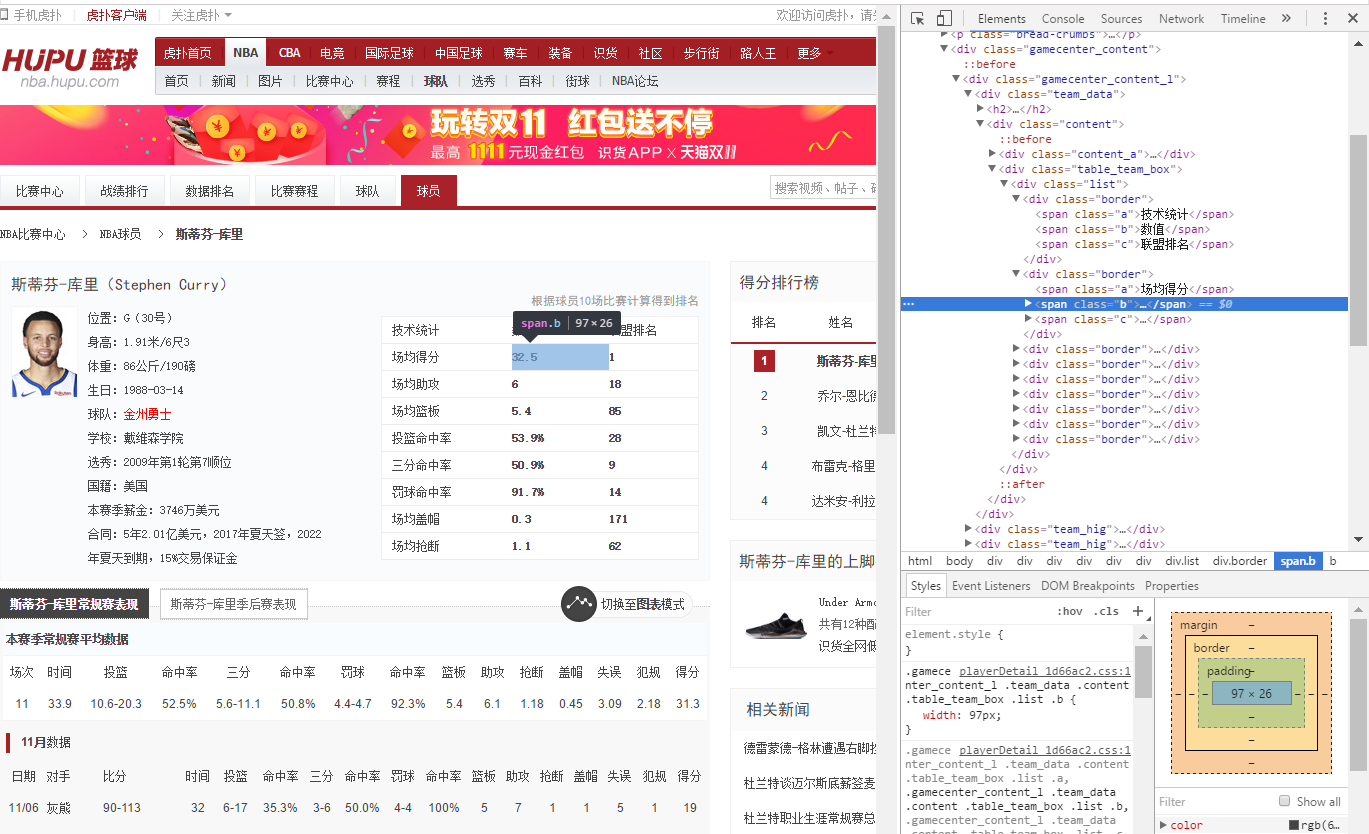
同样用浏览器的代码检查功能,定位到球员的个人数据都存储在span.b的元素里,所以到时我们获取球员个人信息时只要定位到这个标签提取其文本信息就行了
基本的思路就是这样,接下来直接贴代码了(代码后有详细的注释,包括我遇到的一些问题)整个爬取过程大概要十几二十分钟
有几个值得注意的点(部分也是我遇到的问题):
1.得分排行榜的网页一共六页,网址间有很好的关系
https://nba.hupu.com/stats/players/pts/1
https://nba.hupu.com/stats/players/pts/2
第二页和第一页只差一,所以可以用一个遍历循环分别定位到六页网页
2.善于运用try,except,只有自己不断的试才能发现这个东西真的好用,特别是在爬网页的时候,有些数据是空的,用个pass跳过就好了,不然就会一直卡在那
3.注意泰森-钱德勒,泰森-钱德勒,这个人被太阳买断了,然后点进他的主页没有数据,你不用try,except就会卡在那,而且因为球员的姓名我们是在球员得分榜(页面一)获取的,而个人信息是在球员个人主页(页面二)获取的,钱德勒相当于有姓名但没有个人信息,所以在爬钱德勒的时候,只有他的名字没有其他信息,但是爬下一个球员时,信息会向上替补,所有会出现信息混乱的情况,幸好钱德勒排在了倒数几位,所以只要打开生成txt手动调一下就好了,当然也可以用代码删掉钱德勒,不爬他,但我觉得太麻烦就没搞
4.得分、助攻、抢断等信息一定要对应,值得注意的是得分是span.b的第二条信息,第一条是‘数值’,藏在div.border里了

5.我用的是chrom,网上没有火狐浏览器的selenium,geckodriver对应版本,要自己一个一个试,很头疼的,谷歌浏览器及其对应的chromdriver可以很容易在网上找到
制作球员能力雷达图重点不在于怎么画雷达图(雷达图参考的是霍兰德人格分析),而在于怎么分析处理数据
这一块就不具体分析步骤了,直接贴代码,提一下需要注意的点
值得注意的点
1.我们存进文件的是按字符串形式存进去的,不能直接用np.loadtxt以矩阵形式提取出来,需要存到列表里,不能直接转成矩阵进行批量运算,而且也不能以a[:,0]的形式去提取一列,会报错,可以用a=(x[0] for x in data的方式提取
2.因为提取出来的是字符串,所以要去掉双引号进行比较
3.雷达图需要我们统一各个数值的大小,所以我们以每个值与最大值的比来表示这个值代表的大小,这里有个容易忽略的点,我们提取的投篮命中率和三分命中率是带有百分号的,无法比较,所以需要去掉百分号,具体方法代码和注释应该解释的很清楚了
4.如果你按照一般雷达图的代码去生成雷达图,会发现网格线上会标有对应的数值,就像,这里的0.2、0.4、0.6一样,但我这七个角代表的数值显然不是0.2之类的,所以强迫症表示很想把它去掉,但是网上关于python雷达图制作系统的参数介绍几乎没有,博主找了好多图,比较了代码才发现这个怎么去掉,具体可以看看代码和注释

我们输入其他球员试试,老詹和球哥


整个实现过程就是这样了,效果达到了,不过还有很大的优化空间,有时间再优化优化,先存着,权当记录和参考
最后,什么都不说了,湖人总冠军!









评论留言